不存在的套件,真實的威脅:LLM 誤導開發者走入 Slopsquatting 陷阱
- 發布單位:TWCERT/CC
- 更新日期:2025-04-30
- 點閱次數:26121

近年來開發人員在程式開發過程中,時常依賴大型語言模型(LLM)生成的程式碼進行編譯與整合。然而,這些AI模型經常「幻想」不存在的程式碼和函式庫,且這類幻覺具有一定程度的重複性與規律性。資安研究員Seth Larson為此創造「slopsquatting」一詞,專指利用錯誤的函式庫名稱發動的攻擊。若攻擊者針對AI模型所「幻想」的虛假函式庫進行精心設計並發布相應的惡意套件,誘使開發人員將其載入專案中,進而引發嚴重的供應鏈攻擊與軟體安全風險。
此研究由UTSA博士生Joe Spracklen領導,聚焦於LLM在程式碼生成過程中頻繁產生不安全或不存在的函式庫名稱問題,並已投稿於USENIX 2025資安研討會。研究團隊利用二組獨特的資料集,針對包含GPT-4、Claude、CodeLlama、DeepSeek Coder及Mistral等多款主流AI模型進行實驗,收集576,000筆Python與JavaScript程式碼範例。研究結果顯示,將近20%函式庫並不存在,且這些幻想的函示庫名稱被AI模型反覆生成。圖1為此篇論文內敘述如何利用LLM幻覺產生函式庫之流程圖。
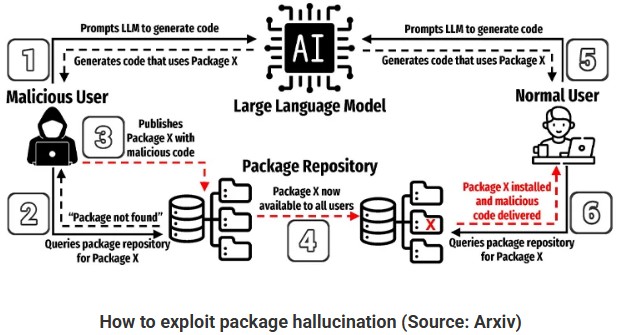
圖1:利用LLM幻覺產生的函式庫之流程圖,圖片來源:Arxiv
為了驗證LLM是否會反覆生成相同的幻覺套件名稱,研究團隊選取500個提示的隨機樣本,並對每個提示進行10次重複查詢。實驗結果顯示,43%的幻覺套件在所有重複查詢中均被持續生成;39%的幻覺套件則未在重複查詢中再次出現。此外,有58%的情況下,幻覺套件會在多次查詢中重複出現,進一步證實LLM生成虛假套件名稱的頻繁且具有規律性的特徵。
根據研究數據顯示,在利用AI模型生成的程式碼中,Python相較於JavaScript出現幻覺套件的比例較低;另外,在各類的AI模型中,GPT系列模型生成的幻覺套件數量少於其他開源AI模型。
研究人員建議開發人員使用AI模型生成程式碼時,務必自行檢查AI所提供的程式碼及其函式庫,避免誤用攻擊者精心設計的惡意程式庫。切勿盲目相信AI輸出的內容,才能有效降低遭受供應鏈攻擊及其他資安風險的可能性。