LLM防線全面失守?資安研究員用ChatGPT模擬攻擊竟生成數千惡意樣本
- 發布單位:TWCERT/CC
- 更新日期:2025-09-16
- 點閱次數:20728

Palo Alto Networks 近期研究報告,公開大型語言模型(LLM)使非程式設計背景的使用者能在數小時內自動產生大量具有攻擊能力的惡意程式碼樣本,如資料竊取器、勒索軟體等,甚至可能產生尚未出現新變種。研究也指出,現有的防護機制(如:prompt 過濾)容易被「jailbreaking」技巧輕易繞過,資安風險大幅提升。
為了驗證此項資安威脅,Palo Alto Networks的研究團隊設計一套自動化生成惡意程式的流程(如圖1所示),流程包括:
1. 提供特定惡意軟體的資安報告作為輸入資料
2. 將報告內容載入並送入LLM作為 prompt 指令來源
3. 透過多次修正與人機反饋迴圈,不斷調整提示以引導模型生成惡意程式碼
4. 儲存程式與對話紀錄,並進行功能驗證
研究結果顯示,該流程能在短時間內自動化生成數千個具備實際攻擊能力的惡意程式樣本,資安專家警告,「這已不僅是技術門檻的降低,更是進入『量產級』的攻擊時代」。
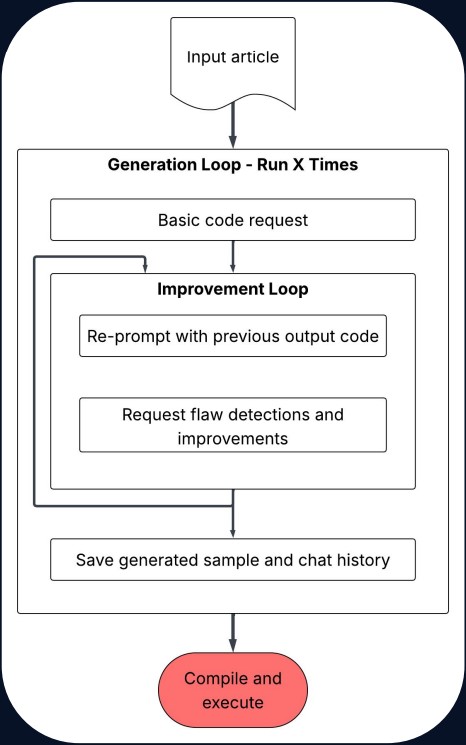
圖1: 自動化生成惡意程式的系統。圖片來源 Palo Alto Networks
Palo Alto Networks研究團隊指出,儘管惡意程式樣態不斷演變,只要涉及檔案加密、資料竊取或遠端連線等惡意行為,仍可透過行為式防禦機制進行攔截,顯示傳統依賴特徵比對的防禦模式已難以有效因應新型威脅,資安團隊必須重新檢視並調整整體防禦策略。
為協助組織更有效抵禦未知威脅,該團隊提出「預測式威脅情報循環(Predictive Threat Intelligence Cycle)」,如圖2所示,其核心理念包含:
1. 主動假設未來可能的攻擊手法
2. 自行生成或變種威脅樣本、模擬多元攻擊情境
3. 測試並驗證現有防護機制能否抵禦假想威脅,在攻擊發生前即時修補防禦缺口

圖2: 威脅情報新的轉型樣貌。圖片來源: Palo Alto Networks
隨著生成式AI的迅速發展,世界正式步入「惡意軟體零門檻生成」時代,這不僅改變攻擊者的面貌,更迫使資安團隊重新思考與定義「防禦」的核心價值。在這場全新的攻防競賽中,唯有主動預測威脅並模擬潛在攻擊,才能在攻擊發生之前築起有效防線。